
API Proxy Service: Simplify Integration & Protect Backends
Published on July 3, 2026
Tags:
You finally get a third party API integrated, your OAuth flow passes, the first request succeeds, and then the weird stuff starts. A token expires sooner than your job runner expects. One platform returns useful JSON errors, another gives you a vague status and makes you poll. A media workflow hangs in progress, and now your support inbox has screenshots instead of stack traces.
This is the part nobody mentions in shiny API launch posts. The hard part usually isn't sending the first request. It's surviving months of inconsistent auth rules, changing payloads, brittle retries, and backend logic that slowly turns into a pile of platform-specific exceptions. If you're building against social platforms or any messy external ecosystem, you don't need more endpoint wrappers. You need a boundary.
Table of Contents
The API Integration Nightmare You Know Too Well
If you've ever integrated multiple external APIs directly from your application code, you already know the shape of the mess. It starts innocently. One provider needs OAuth. Another wants a long-lived key. A third requires a multi-step publishing flow that doesn't map cleanly to your product at all. You add branches, adapters, retry conditions, and special error handling. Three sprints later, your clean service layer looks like archaeology.
Social APIs are where this gets especially painful. A direct publish endpoint on one platform doesn't help when another expects a staged upload flow, background processing, and a separate publish call after the asset becomes ready. Your app code ends up learning too much about systems it doesn't control. That coupling is what hurts.
You can usually tell an integration is drifting when product changes start requiring backend edits in three different places just to support one external API quirk.
The maintenance burden doesn't stay small. The more external services you touch, the more your codebase turns into a compatibility layer. Even documentation becomes work. Teams often need internal guides just to explain why one connector retries on one status but not another. If you're trying to improve that side of the work, top API docs for founders is a useful roundup of tools that make complex integrations easier to explain and maintain.
There's also a larger adoption signal behind all this. As of 2026, 48% of businesses deploy proxy technologies primarily for web scraping and data extraction, while approximately 30% of global internet users have utilized a proxy or VPN, which shows how normal proxy-based access patterns have become in data-heavy systems, according to proxy industry statistics from WiFiTalents.
The pain shows up in code
The problem usually isn't one endpoint. It's the accumulation of concerns:
Authentication drift: one token lifecycle doesn't match another, so your scheduler and your request pipeline start carrying auth logic they shouldn't own.
Schema mismatch: your app wants one content model, but every provider names fields differently and expects different nesting.
Failure semantics: some APIs fail loudly, others fail asynchronously, and your product still has to present one coherent status to users.
Rate control: provider limits leak into your app code until every queue worker needs custom pacing logic.
A lot of teams hit this wall when they start consolidating social publishing, reporting, or ingestion. That's why architectural discussions around social media platform integration eventually stop being about SDKs and start being about boundaries.
What Exactly Is an API Proxy Service
An API proxy service is the layer that sits between your app and one or more backend APIs and makes those interactions safer, cleaner, and easier to control. The simplest analogy is a diplomatic translator. Your app speaks one language. The backend service speaks another. The proxy handles the conversation, enforces rules, and makes sure nobody has direct access they shouldn't have.
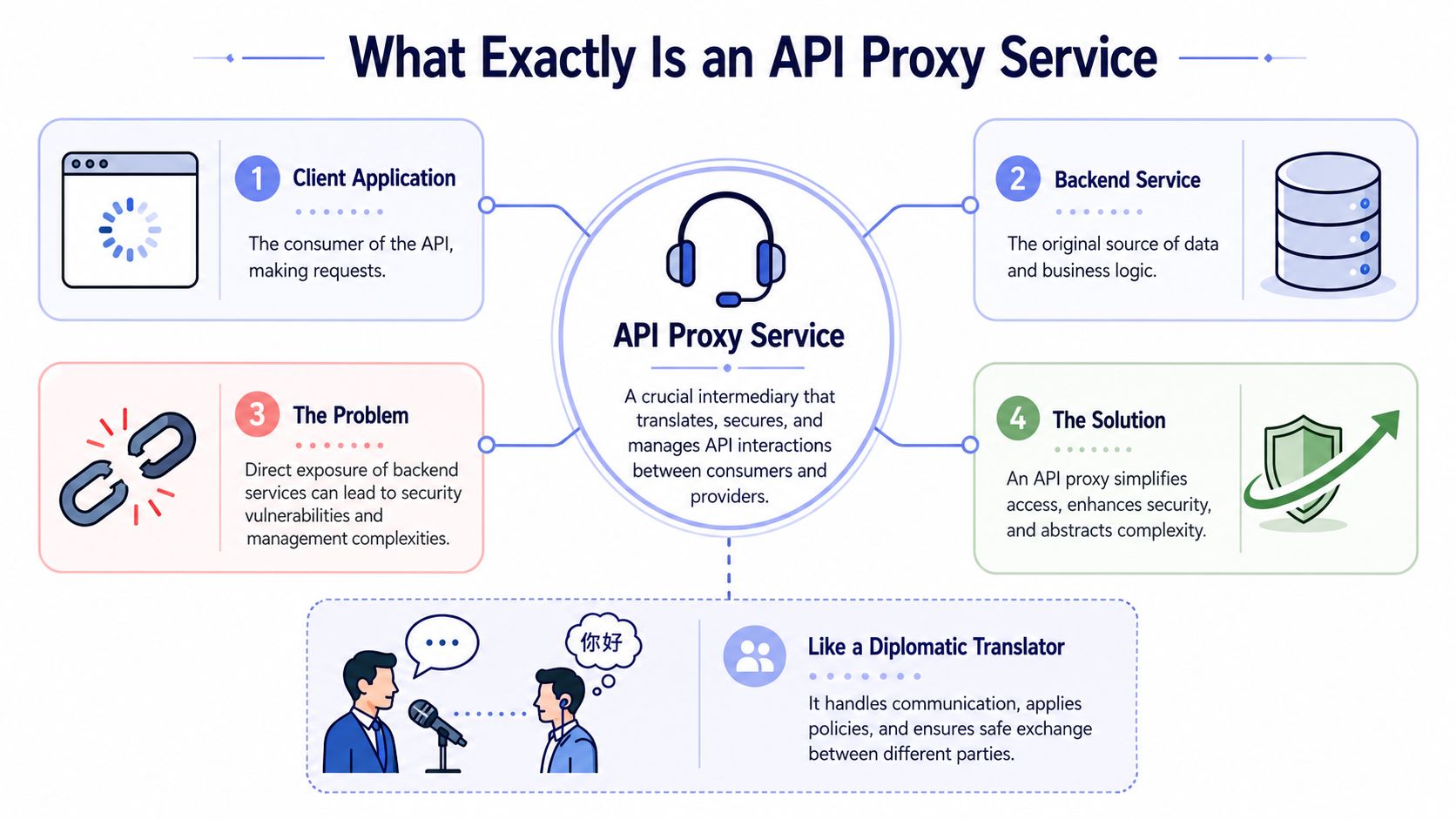 A diagram explaining API proxy services, showing their role as intermediaries between client applications and backend services.
A diagram explaining API proxy services, showing their role as intermediaries between client applications and backend services.The short version
A good API proxy doesn't just forward requests. It gives you one controlled entry point where you can inspect traffic, apply auth policies, normalize payloads, cache repeated responses, and shield backend systems from direct exposure. That's the practical definition that matters in day to day engineering.
The official description from API2Cart is close to how most integration engineers think about it in practice. An API proxy service acts as an abstraction layer that routes requests between clients and backend APIs while enhancing security, caching, and rate limiting without changing the original API, as described in API2Cart's explanation of API proxy services.
A tiny example makes this concrete. Without a proxy, your frontend or app service may need platform-specific logic:
With a proxy, your application can call a single stable endpoint like POST /publish, and the proxy handles the provider-specific flow behind it. Your app stops caring how many backend calls are needed.
Practical rule: If your client code knows too much about third party workflow choreography, that logic probably belongs in a proxy layer.
A visual walkthrough helps if you're explaining the pattern to teammates or clients.
Why this pattern matters
The biggest win is decoupling. Your client application talks to a stable contract, while the proxy absorbs backend irregularities. That means you can introduce policy checks, remap fields, or swap backend implementations without forcing a client update every time a provider changes something.
This pattern is especially useful when backends are heterogeneous. One service returns XML, another returns nested JSON, and a third has a custom auth handshake. The proxy becomes your normalization point. It doesn't need to own business logic, but it should own integration logic.
That distinction matters. An API proxy service isn't a random extra hop. It's the place where you intentionally separate product behavior from provider mechanics.
Core Architecture and Superpowers
Once you put an API proxy service in front of messy integrations, a bunch of previously scattered concerns move into one controllable layer. This consolidation provides significant advantages. You're not adding complexity for fun. You're relocating complexity to the place where it can be standardized.
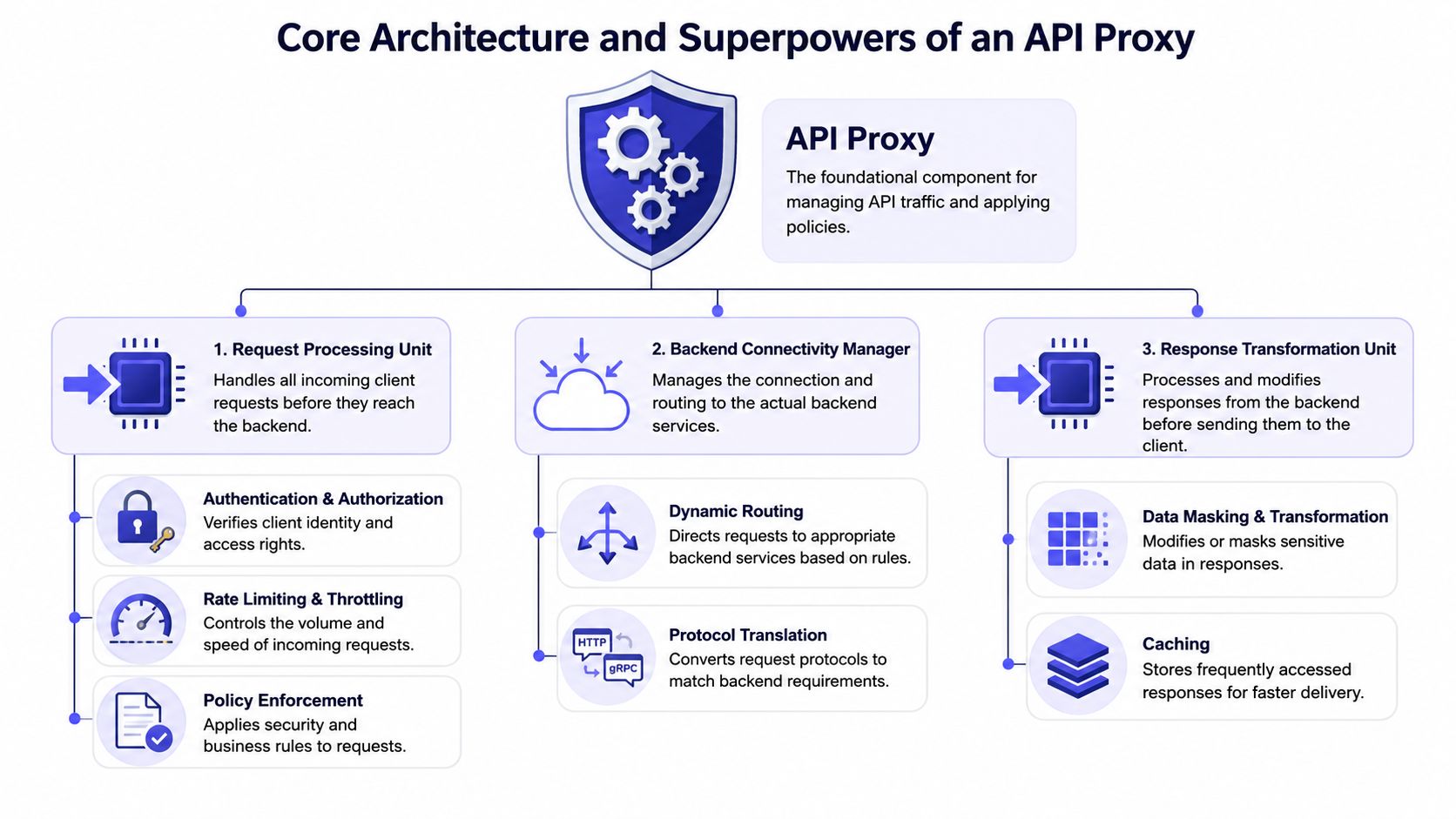 A diagram illustrating the core architecture and functions of an API proxy, including request, backend, and response management.
A diagram illustrating the core architecture and functions of an API proxy, including request, backend, and response management.Request shaping and translation
The first superpower is transformation. A proxy can intercept requests, validate them, remove fields a backend doesn't need, and convert formats before forwarding traffic. That sounds basic until you have mobile clients, internal tools, automation platforms, and AI agents all hitting the same backend in slightly different ways.
This is also where proxies clean up inconsistent provider schemas. If one backend expects a nested media object and another wants a flat structure, the proxy can map both to one internal contract. Your app gets one predictable surface.
According to Tyk's discussion of proxies, gateways, and service meshes, an API proxy can reduce payload size by up to 40% through field filtering and reduce latency by 250ms through intelligent caching, while converting different data formats into a consistent schema. Those are exactly the kinds of wins that matter when your clients include mobile apps, automations, and latency-sensitive workflows.
A practical request pipeline often looks like this:
Validate input early: reject malformed or dangerous payloads before they hit your backend.
Normalize the contract: map client-friendly fields into provider-specific shapes.
Attach credentials centrally: keep API keys and tokens out of client code where possible.
Route by rule: send the request to the right upstream based on tenant, region, capability, or provider type.
Caching, routing, and observability
The second superpower is traffic management. Some requests shouldn't hit the backend every time. Health metadata, account capabilities, reusable profile data, and slowly changing resources are all good candidates for proxy-level caching. That doesn't replace good backend caching, but it gives you another lever that you can tune without rewriting application code.
Routing is where many teams underestimate the value of a proxy. A backend migration becomes much easier when the client keeps calling the same public contract and the proxy decides which upstream to use. Blue-green changes, version transitions, and provider swaps become operational decisions instead of application rewrites.
Keep routing rules declarative when you can. Once routing logic turns into scattered custom code, your proxy starts inheriting the same maintenance problem it was supposed to solve.
Observability also gets cleaner. Instead of scraping logs from several services to understand one failing call, you can centralize request IDs, auth outcomes, transformation errors, and upstream timings at the proxy boundary. That gives you a single place to answer the most common integration question: did the request fail before the backend, inside the backend, or after the backend returned something unexpected?
A well-designed proxy usually owns these operational jobs:
Central logging: correlate inbound requests with outbound upstream calls.
Response shaping: redact fields, flatten noisy responses, or standardize error envelopes.
Selective caching: speed up repeated lookups without making clients know what is cacheable.
Protocol mediation: bridge systems that don't expose the same transport or payload conventions.
The pattern works best when the proxy stays focused. It should be opinionated about integration concerns and conservative about business logic.
API Proxy vs Gateway vs Reverse Proxy
A lot of integration pain starts with sloppy terminology. A team says it needs "a proxy," then ends up buying gateway software for a single third-party API, or trying to force NGINX to normalize five different OAuth flows from social platforms. Those are expensive mistakes.
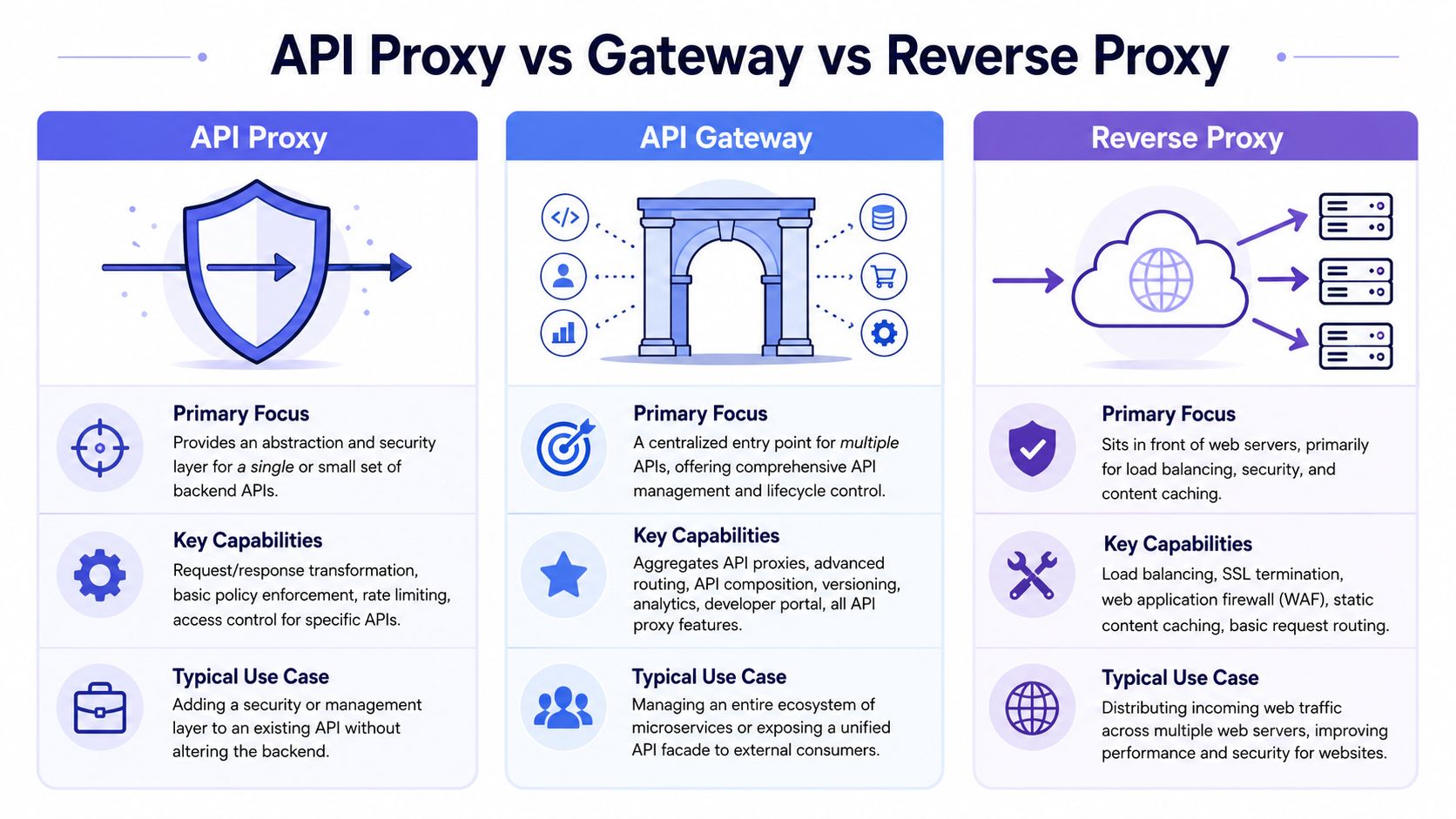 A comparison chart outlining the differences, primary focus, capabilities, and use cases of API Proxy, Gateway, and Reverse Proxy.
A comparison chart outlining the differences, primary focus, capabilities, and use cases of API Proxy, Gateway, and Reverse Proxy.The fast comparison
Pattern | Main job | Best fit | What it usually handles |
API proxy | Adapt and protect API interactions | A specific integration boundary or a small set of APIs | Transformation, policy checks, auth handling, caching, rate control |
API gateway | Provide a managed front door for many APIs | A broader platform or microservices estate | Aggregation, lifecycle management, advanced routing, analytics, developer-facing API management |
Reverse proxy | Sit in front of servers and manage web traffic | Websites, web apps, and infrastructure traffic flow | Load balancing, TLS termination, content caching, basic request forwarding |
The table helps, but the main distinction is scope.
A reverse proxy sits close to infrastructure. Its job is to accept traffic, forward it efficiently, terminate TLS, cache where appropriate, and shield origin servers. It is perfect for web delivery and traffic management. It usually does not care that one upstream is LinkedIn, another is TikTok, and both return different error shapes for the same failed publish request.
An API proxy service sits close to the integration boundary. Its job is to make one ugly API, or several ugly APIs, feel consistent to the client. That means inspecting payloads, applying API-specific auth rules, translating headers, reshaping responses, and hiding provider quirks. For teams dealing with inconsistent third-party APIs, this is often the missing layer that turns a brittle integration into a maintainable one.
An API gateway is broader. It acts as the front door for many APIs and usually adds governance features around them: productization, developer access, versioning, analytics, and centralized policy management. In practice, a gateway often includes proxy capabilities, but its mandate is wider than cleaning up a single messy provider integration.
When each one fits
Use a reverse proxy when the problem is traffic flow. If the work is load balancing, TLS termination, static caching, or origin protection, keep the solution close to the edge and keep it simple.
Use an API proxy when the problem is API inconsistency. This is the pattern that earns its keep when Meta uses one auth convention, X uses another, and your frontend team still expects one stable contract. It is also the right place to centralize provider credentials, especially if you are already tightening API key management for distributed integrations.
Use an API gateway when the problem is platform scale. If dozens of internal services and external consumers need one governed entry point, a gateway justifies its cost.
There is overlap, and that is where teams get confused. A gateway can proxy requests. A reverse proxy can apply simple policies. An API proxy can sit behind a gateway. The useful question is not which label sounds closest. The useful question is which component owns the responsibility you have.
For example, if a data pipeline keeps breaking because one upstream API changes rate limits, another changes pagination, and a third returns partial failures in a format nobody normalized, an API proxy is usually the cleanest fix. It gives you one place to absorb those differences before they spread into workers, dashboards, and retry logic. That same pattern shows up in preventing AI data pipeline failures, where the proxy layer reduces upstream inconsistency before it cascades through downstream systems.
A reverse proxy protects servers. An API proxy protects API interactions. A gateway governs an API estate.
Production systems often use all three. A reverse proxy handles edge traffic. A gateway manages the broader API program. A targeted API proxy cleans up the integrations everyone complains about in standups. The mistake is not combining patterns. The mistake is expecting one layer to solve a different class of problem.
Common Use Cases and Security Patterns
A proxy earns its keep the first time a third party changes behavior on a Friday afternoon and your app does not need a hotfix. Instead of patching auth checks, retry rules, and request shaping across multiple services, teams put that control at one boundary and keep the rest of the code focused on business logic.
 A hand-drawn illustration showing an API proxy shield protecting a server, managing traffic and security policies.
A hand-drawn illustration showing an API proxy shield protecting a server, managing traffic and security policies.Security policies that belong in the proxy
Access control is the obvious starting point. Authentication and authorization are easier to audit when they happen in one place instead of being reimplemented across workers, admin tools, and customer-facing endpoints. Backends still need service-to-service trust rules, but the proxy should reject bad requests before they touch anything expensive or sensitive.
The same logic applies to secrets. Provider credentials should not be scattered through cron jobs, support scripts, and frontend code paths that grew by accident over time. Centralizing that layer in the proxy simplifies rotation, limits exposure, and makes failures easier to diagnose. If you are tightening that part of your stack, this guide to API key management patterns is a useful companion read.
Three controls usually pay off fast:
Per-consumer throttling: stop one tenant, integration script, or background job from consuming shared upstream capacity.
Input validation: reject malformed payloads and obviously dangerous input before upstream services waste time processing them.
Credential isolation: keep provider secrets off the client and out of low-visibility automation code.
Bad traffic is cheapest to stop at the API boundary, before it reaches code that was never meant to defend itself from every upstream mistake.
Operational patterns that reduce pain
Operationally, the proxy is also where teams implement boring but valuable rules. Standardize error envelopes. Normalize timeout behavior. Add request IDs. Mask sensitive values in logs. Translate provider-specific failures into responses your frontend and job workers can handle without custom parsing for each integration.
That matters most when the upstream APIs are inconsistent. Social platforms are a familiar example. One returns partial success, another times out after accepting work, and a third changes a validation rule without changing its status codes. Without a proxy, those quirks leak into every client and every background process.
The same pattern shows up outside user-facing apps. In data pipelines and automation systems, one odd upstream response can break a chain of jobs that were written against a cleaner contract. For a practical look at that failure mode, preventing AI data pipeline failures gives a useful framing of why proxy layers matter beyond traditional web apps.
A reliable proxy policy set often includes:
Consistent retry boundaries: retry only failures that are safe to repeat, and keep that rule out of feature code.
Response sanitization: remove internal-only fields before data leaves your boundary.
Traffic segmentation: send internal tools, customer traffic, and automation jobs through different policy paths when they need different limits or logging behavior.
The best setups keep these rules visible and declarative. Once they disappear into custom middleware scattered across repositories, the proxy stops being a clean control point and turns into another source of integration drift.
Example in Action The PostPulse Unified Social API
The easiest way to understand an API proxy service is to look at one that's solving a real integration mess. Social publishing is a good example because the backend environment is fragmented by design. Every platform has its own auth model, content constraints, media workflows, error semantics, and version churn.
PostPulse works like a specialized proxy layer in front of that complexity. Instead of asking a product team to integrate each social platform separately, it exposes one unified API surface for publishing. The app-facing contract stays stable while platform-specific mechanics are handled behind that boundary.
Google's Apigee documentation describes the key idea well: API proxies decouple the app-facing API from backend services so client apps can consume a stable API without being exposed to backend code changes, which shields them from internal service modifications, as explained in Apigee's guide to understanding API proxies.
This is the core value here. A client app doesn't need to know which platform needs a staged media flow, which one has a different publishing sequence, or which provider changed behavior in a new API version. The client integrates once against a stable contract, and the proxy layer absorbs the churn.
If you're evaluating what that kind of unified surface looks like in practice, the PostPulse API docs show the app-facing side of the pattern clearly. One API abstracts a messy backend ecosystem into something a product team can ship against.
If you're building social publishing into a SaaS product, an automation flow, or an AI agent, PostPulse is worth a look. It gives you one integration for publishing to 9 platforms through a REST API, official n8n and Make.com nodes, or an MCP server, while handling the backend churn that usually turns social API work into maintenance debt.
About the Author
Founder of PostPulse — a social media scheduling platform for creators and teams. Software engineer with a passion for building developer tools and simplifying complex API integrations across social media platforms.